 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Embedded Multiplicative DMD for Algebra-Preserving Koopman Learning
Jun 03, 2026Koopman theory turns nonlinear dynamics into a linear spectral problem. In computation, however, everything depends on a hard finite-dimensional choice: the observables must be expressive, nearly invariant under the dynamics, and, ideally, compatible with composition. Deep Koopman methods learn flexible coordinates, whereas structure-preserving methods enforce operator identities on fixed dictionaries. We combine these ideas by introducing Deep Embedded Multiplicative Dynamic Mode Decomposition (DeepMDMD), a method that learns a latent space and a partition of it, while enforcing the Koopman product rule as an exact algebraic constraint. Training alternates between an exact multiplicative operator update and a differentiable latent-clustering step that promotes Koopman closure. The result is a finite transition map on learned latent cells. Its nonzero spectrum lies on the unit circle, its dictionary is shaped by the dynamics rather than by ambient geometry, and forecasts are made in latent coordinates before being decoded to physical space. Across Hamiltonian, chaotic, and fluid examples, DeepMDMD learns dictionaries that are far more compact and dynamically coherent than those produced by geometric MDMD partitions. It reduces spectral pollution, reveals richer continuous-spectrum structure, and gives stable forecasts under severe noise. In high-dimensional flows, including a 158,624-dimensional cylinder wake and a noisy $Re=20,000$ lid-driven cavity, it preserves coherent structures and long-time spectral statistics where state-space MDMD fails. These results suggest a practical rule for Koopman learning: learn the coordinates, constrain the algebra.
Generalized Discrete Diffusion from Snapshots
Mar 22, 2026We introduce Generalized Discrete Diffusion from Snapshots (GDDS), a unified framework for discrete diffusion modeling that supports arbitrary noising processes over large discrete state spaces. Our formulation encompasses all existing discrete diffusion approaches, while allowing significantly greater flexibility in the choice of corruption dynamics. The forward noising process relies on uniformization and enables fast arbitrary corruption. For the reverse process, we derive a simple evidence lower bound (ELBO) based on snapshot latents, instead of the entire noising path, that allows efficient training of standard generative modeling architectures with clear probabilistic interpretation. Our experiments on large-vocabulary discrete generation tasks suggest that the proposed framework outperforms existing discrete diffusion methods in terms of training efficiency and generation quality, and beats autoregressive models for the first time at this scale. We provide the code along with a blog post on the project page : \href{https://oussamazekri.fr/gdds}{https://oussamazekri.fr/gdds}.
Trustworthy Koopman Operator Learning: Invariance Diagnostics and Error Bounds
Mar 16, 2026Koopman operator theory provides a global linear representation of nonlinear dynamics and underpins many data-driven methods. In practice, however, finite-dimensional feature spaces induced by a user-chosen dictionary are rarely invariant, so closure failures and projection errors lead to spurious eigenvalues, misleading Koopman modes, and overconfident forecasts. This paper addresses a central validation problem in data-driven Koopman methods: how to quantify invariance and projection errors for an arbitrary feature space using only snapshot data, and how to use these diagnostics to produce actionable guarantees and guide dictionary refinement? A unified a posteriori methodology is developed for certifying when a Koopman approximation is trustworthy and improving it when it is not. Koopman invariance is quantified using principal angles between a subspace and its Koopman image, yielding principal observables and a principal angle decomposition (PAD), a dynamics-informed alternative to SVD truncation with significantly improved performance. Multi-step error bounds are derived for Koopman and Perron--Frobenius mode decompositions, including RKHS-based pointwise guarantees, and are complemented by Gaussian process expected error surrogates. The resulting toolbox enables validated spectral analysis, certified forecasting, and principled dictionary and kernel learning, demonstrated on chaotic and high-dimensional benchmarks and real-world datasets, including cavity flow and the Pluto--Charon system.
Jacobian Scopes: token-level causal attributions in LLMs
Jan 23, 2026Large language models (LLMs) make next-token predictions based on clues present in their context, such as semantic descriptions and in-context examples. Yet, elucidating which prior tokens most strongly influence a given prediction remains challenging due to the proliferation of layers and attention heads in modern architectures. We propose Jacobian Scopes, a suite of gradient-based, token-level causal attribution methods for interpreting LLM predictions. By analyzing the linearized relations of final hidden state with respect to inputs, Jacobian Scopes quantify how input tokens influence a model's prediction. We introduce three variants - Semantic, Fisher, and Temperature Scopes - which respectively target sensitivity of specific logits, the full predictive distribution, and model confidence (inverse temperature). Through case studies spanning instruction understanding, translation and in-context learning (ICL), we uncover interesting findings, such as when Jacobian Scopes point to implicit political biases. We believe that our proposed methods also shed light on recently debated mechanisms underlying in-context time-series forecasting. Our code and interactive demonstrations are publicly available at https://github.com/AntonioLiu97/JacobianScopes.
Multi-Level Monte Carlo Training of Neural Operators
May 19, 2025Operator learning is a rapidly growing field that aims to approximate nonlinear operators related to partial differential equations (PDEs) using neural operators. These rely on discretization of input and output functions and are, usually, expensive to train for large-scale problems at high-resolution. Motivated by this, we present a Multi-Level Monte Carlo (MLMC) approach to train neural operators by leveraging a hierarchy of resolutions of function dicretization. Our framework relies on using gradient corrections from fewer samples of fine-resolution data to decrease the computational cost of training while maintaining a high level accuracy. The proposed MLMC training procedure can be applied to any architecture accepting multi-resolution data. Our numerical experiments on a range of state-of-the-art models and test-cases demonstrate improved computational efficiency compared to traditional single-resolution training approaches, and highlight the existence of a Pareto curve between accuracy and computational time, related to the number of samples per resolution.
Fine-Tuning Discrete Diffusion Models with Policy Gradient Methods
Feb 03, 2025



Discrete diffusion models have recently gained significant attention due to their ability to process complex discrete structures for language modeling. However, fine-tuning these models with policy gradient methods, as is commonly done in Reinforcement Learning from Human Feedback (RLHF), remains a challenging task. We propose an efficient, broadly applicable, and theoretically justified policy gradient algorithm, called Score Entropy Policy Optimization (SEPO), for fine-tuning discrete diffusion models over non-differentiable rewards. Our numerical experiments across several discrete generative tasks demonstrate the scalability and efficiency of our method. Our code is available at https://github.com/ozekri/SEPO
Operator learning regularization for macroscopic permeability prediction in dual-scale flow problem
Nov 30, 2024



Liquid composites moulding is an important manufacturing technology for fibre reinforced composites, due to its cost-effectiveness. Challenges lie in the optimisation of the process due to the lack of understanding of key characteristic of textile fabrics - permeability. The problem of computing the permeability coefficient can be modelled as the well-known Stokes-Brinkman equation, which introduces a heterogeneous parameter $\beta$ distinguishing macropore regions and fibre-bundle regions. In the present work, we train a Fourier neural operator to learn the nonlinear map from the heterogeneous coefficient $\beta$ to the velocity field $u$, and recover the corresponding macroscopic permeability $K$. This is a challenging inverse problem since both the input and output fields span several order of magnitudes, we introduce different regularization techniques for the loss function and perform a quantitative comparison between them.
Density estimation with LLMs: a geometric investigation of in-context learning trajectories
Oct 07, 2024Large language models (LLMs) demonstrate remarkable emergent abilities to perform in-context learning across various tasks, including time series forecasting. This work investigates LLMs' ability to estimate probability density functions (PDFs) from data observed in-context; such density estimation (DE) is a fundamental task underlying many probabilistic modeling problems. We leverage the Intensive Principal Component Analysis (InPCA) to visualize and analyze the in-context learning dynamics of LLaMA-2 models. Our main finding is that these LLMs all follow similar learning trajectories in a low-dimensional InPCA space, which are distinct from those of traditional density estimation methods like histograms and Gaussian kernel density estimation (KDE). We interpret the LLaMA in-context DE process as a KDE with an adaptive kernel width and shape. This custom kernel model captures a significant portion of LLaMA's behavior despite having only two parameters. We further speculate on why LLaMA's kernel width and shape differs from classical algorithms, providing insights into the mechanism of in-context probabilistic reasoning in LLMs.
Large Language Models as Markov Chains
Oct 03, 2024



Large language models (LLMs) have proven to be remarkably efficient, both across a wide range of natural language processing tasks and well beyond them. However, a comprehensive theoretical analysis of the origins of their impressive performance remains elusive. In this paper, we approach this challenging task by drawing an equivalence between generic autoregressive language models with vocabulary of size $T$ and context window of size $K$ and Markov chains defined on a finite state space of size $\mathcal{O}(T^K)$. We derive several surprising findings related to the existence of a stationary distribution of Markov chains that capture the inference power of LLMs, their speed of convergence to it, and the influence of the temperature on the latter. We then prove pre-training and in-context generalization bounds and show how the drawn equivalence allows us to enrich their interpretation. Finally, we illustrate our theoretical guarantees with experiments on several recent LLMs to highlight how they capture the behavior observed in practice.
Lines of Thought in Large Language Models
Oct 02, 2024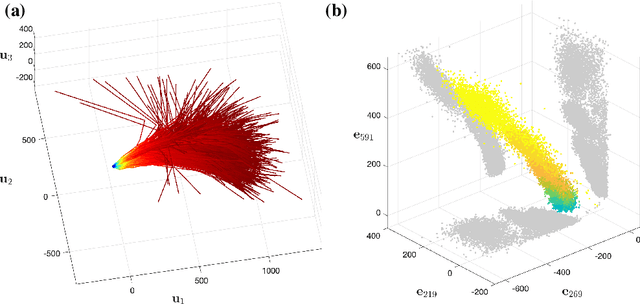
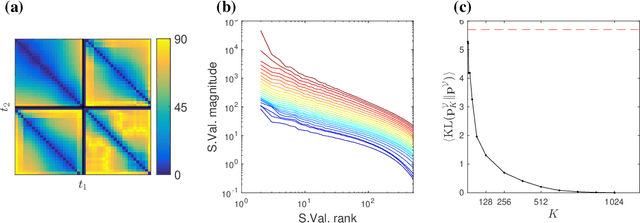
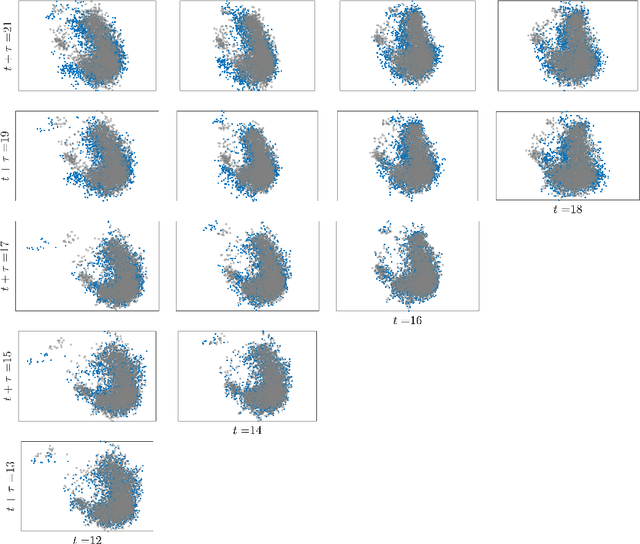
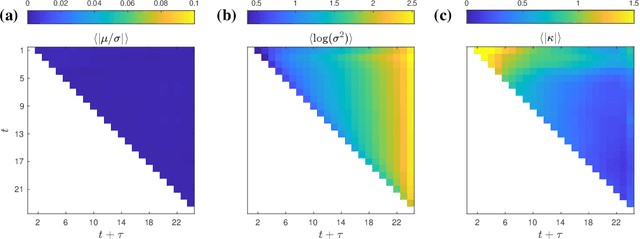
Large Language Models achieve next-token prediction by transporting a vectorized piece of text (prompt) across an accompanying embedding space under the action of successive transformer layers. The resulting high-dimensional trajectories realize different contextualization, or 'thinking', steps, and fully determine the output probability distribution. We aim to characterize the statistical properties of ensembles of these 'lines of thought.' We observe that independent trajectories cluster along a low-dimensional, non-Euclidean manifold, and that their path can be well approximated by a stochastic equation with few parameters extracted from data. We find it remarkable that the vast complexity of such large models can be reduced to a much simpler form, and we reflect on implications.